Let’s get one thing straight! ☝?
Doom (1-second pause) Doom ?️⏳⏳?️
??♀️ is a DIFFERENT sound from
Doom (half a second pause) Doom ?️⏳?️
I need to play those back using real instruments at the right time. To achieve this, I have to do two things:
- Get the timestamps of the sound recognition from my machine learning model in a way that can interact with a web app.
- Play back the sounds at the correct intervals.
Today, I want to chat about the first part. ?
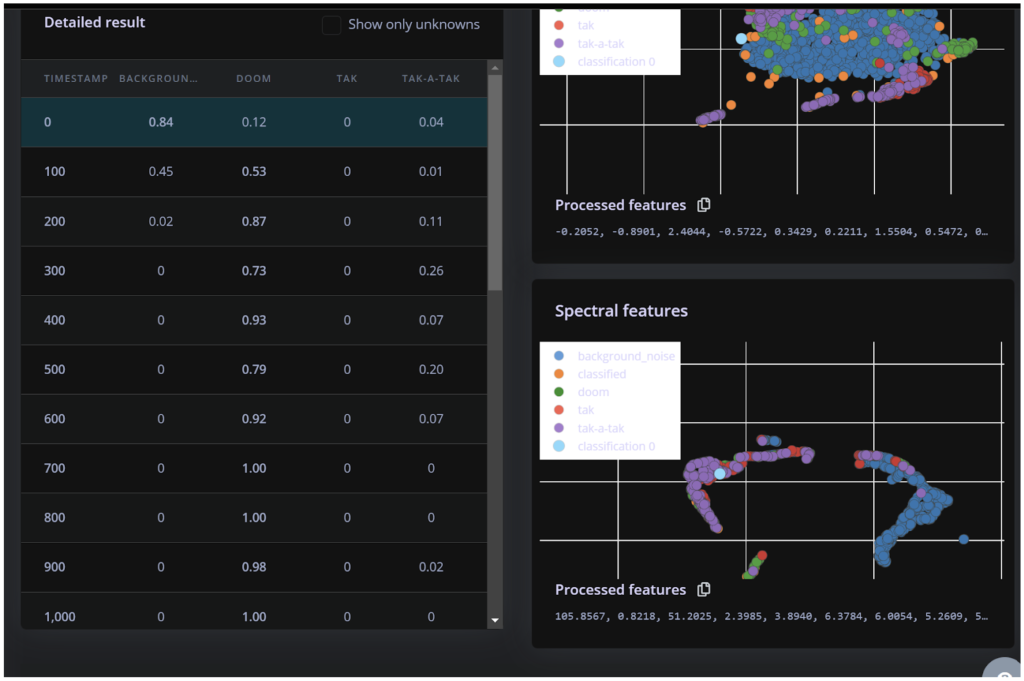
Once I run my machine learning model, it recognises and timestamps when sounds were performed. You can see this in the first photo below. The model shows the probabilities of recognising each sound, such as “doom”, “tak”, or “tak-a-tak”. ?
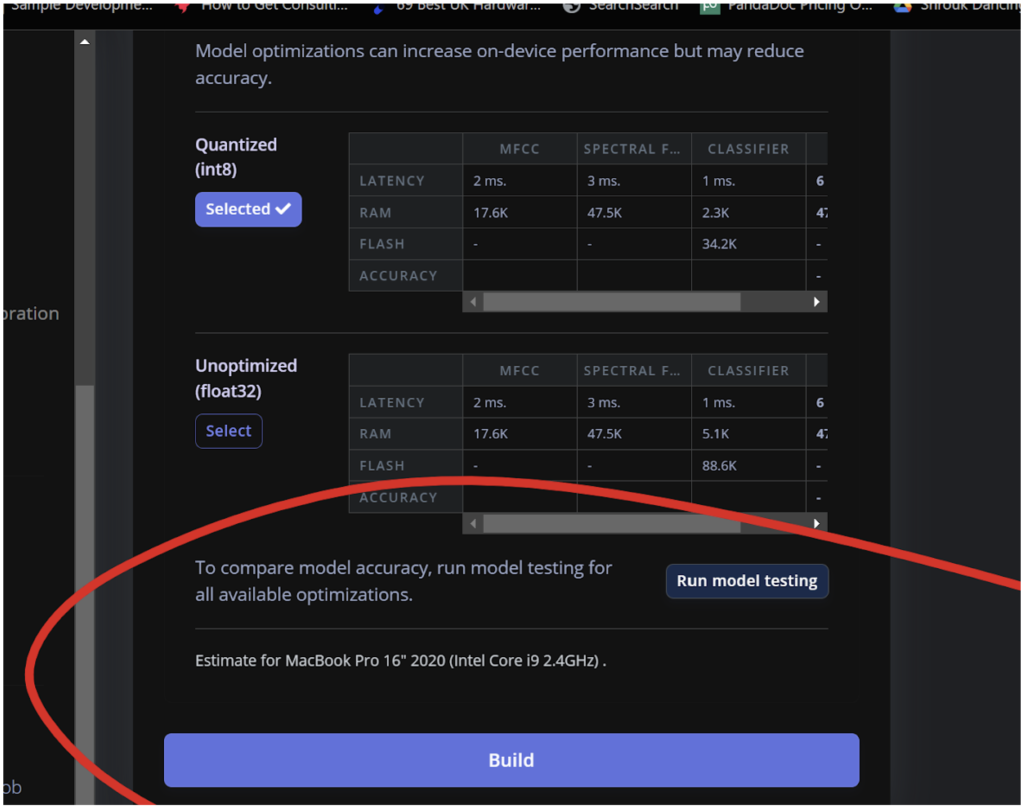
Next, I need to export this model as a WebAssembly package so it can run in a web browser. This allows anyone to interact with my online doom/tak exhibition! ?
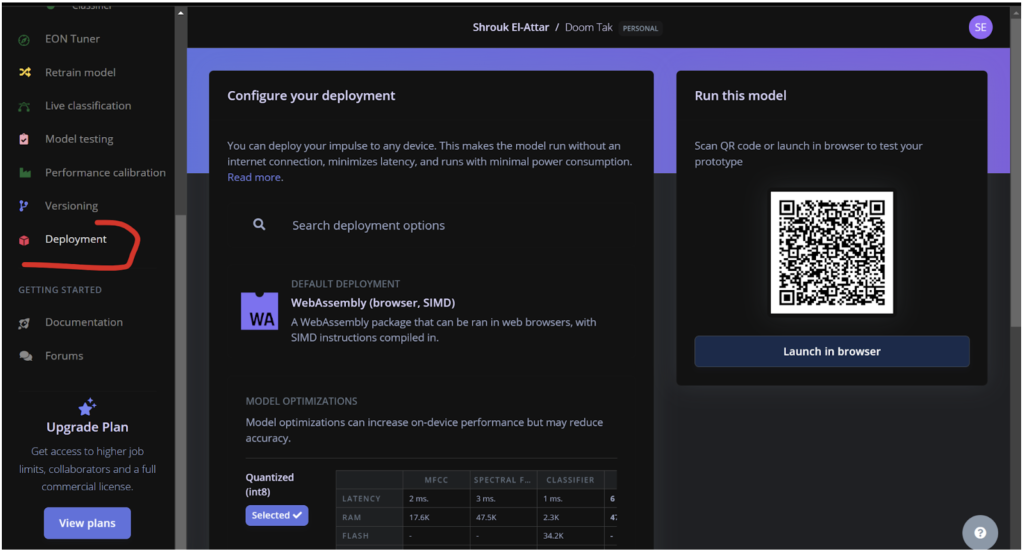
In the second photo, you can see the deployment section where I configure the WebAssembly package. This makes the model run efficiently in web browsers without an internet connection, minimising latency.
Exporting the model is straightforward. Once exported, it generates a JavaScript model that can be used on a webpage. Now, I can call this entire machine learning model from a web app script to do whatever I want.
Easy peasy lemon squeezy! ?